금융 이상 거래 탐지 시스템
금융 빅데이터 기반 실시간 신용카드 사기 탐지 및 모니터링 시스템
프로젝트 개요
"수천 건의 거래 중 단 하나의 사기 거래를 찾아낼 수 있을까요?" 금융 사기 수법이 고도화됨에 따라, 기존의 규칙 기반(Rule-based) 탐지 시스템만으로는 한계가 있습니다.
Anomaly Dashboard는 기계 학습(Machine Learning)을 활용하여 신용카드 사기 거래를 실시간으로 탐지하고 시각화하는 통합 대시보드입니다.
**Kaggle의 유럽 카드 사용자 거래 데이터셋(28만 건)**을 활용하였으며, 전체의 **0.17%**에 불과한 극심한 데이터 불균형 문제를 SMOTE 기법으로 해결했습니다. 초기 비지도 학습 모델의 한계를 극복하고 지도 학습(Random Forest)을 도입하여 최종적으로 **재현율(Recall) 77%**의 성능을 달성했으며, 이를 FastAPI와 React 기반의 대시보드로 구현하여 실시간 모니터링이 가능하도록 했습니다.
프로젝트 구조
Anomaly-Dashboard/
├── backend/ # FastAPI 백엔드 서버
│ ├── app/
│ │ ├── api/ # 예측 및 로그 조회 엔드포인트
│ │ ├── crud/ # 데이터베이스 CRUD 유틸리티
│ │ ├── db/ # DB 연결 및 세션 관리
│ │ └── models/ # SQLAlchemy 모델 정의
│ ├── Dockerfile # 백엔드 컨테이너 설정
│ └── requirements.txt
├── frontend/ # React 프론트엔드
│ ├── src/
│ │ ├── components/ # 대시보드 UI 컴포넌트 (RiskChart, RealtimeLog 등)
│ │ ├── pages/ # 메인 대시보드 페이지
│ │ └── utils/ # API 호출 및 시뮬레이션 데이터
│ ├── Dockerfile # 프론트엔드 컨테이너 설정
│ └── package.json
├── data_train.ipynb # ML 모델 학습 및 전처리 (Jupyter Notebook)
└── docker-compose.yml # 전체 서비스 오케스트레이션기술 스택 및 아키텍처
| 분류 | 기술 |
|---|---|
| Frontend | React, Chart.js, Axios |
| Backend | Python, FastAPI, SQLAlchemy |
| AI / ML | Scikit-learn, SMOTE, Pandas, NumPy, Joblib |
| Database | PostgreSQL |
| Infra | Docker, Docker Compose |
DB 설계
주요 테이블
-- 예측 로그 및 사기 이력 저장
prediction_logs (
id SERIAL PRIMARY KEY,
status VARCHAR, -- 상태 (NORMAL, FRAUD, ERROR)
is_fraud BOOLEAN, -- 사기 여부
probability FLOAT, -- 사기 예측 확률 (0.0 ~ 1.0)
amount FLOAT, -- 거래 금액 (원본)
time FLOAT, -- 거래 시간 (원본)
details VARCHAR, -- 상세 설명 또는 메타데이터
timestamp DATETIME -- 기록 일시
)UI/UX 특징
직관적인 모니터링
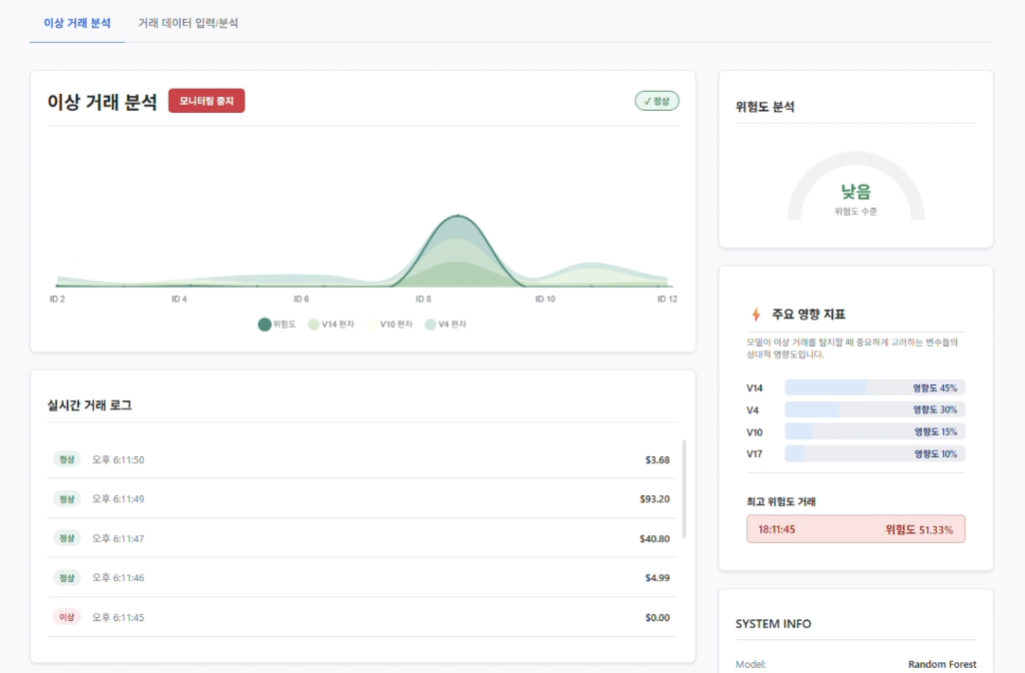
- 실시간 위험도 및 보조 지표 그래프: 위험도 추이와 함께 주요 변수(V14, V10, V4 등)의 편차를 보조 지표로 시각화하여 이상 징후의 원인을 직관적으로 파악
- 상태 배지 시스템: 거래 상태(정상/위험)에 따라 색상 코딩된 배지(Badge) 제공으로 즉각적인 인지
상세 분석 인터페이스
- Z-Score 편차 시각화: 주요 변수(V4, V10, V14 등)의 정상 범위 이탈 정도를 누적 영역 차트로 표현
- 드릴다운(Drill-down) 로그: 리스트 클릭 시 해당 거래의 상세 피처 값과 AI 분석 코멘트 제공
주요 기능
1. 실시간 사기 탐지 및 설명 생성
- 입력된 거래 데이터(PCA 변환된 V1~V28 포함 30개 피처)를 분석하여 1초 이내에 사기 여부를 판별합니다.
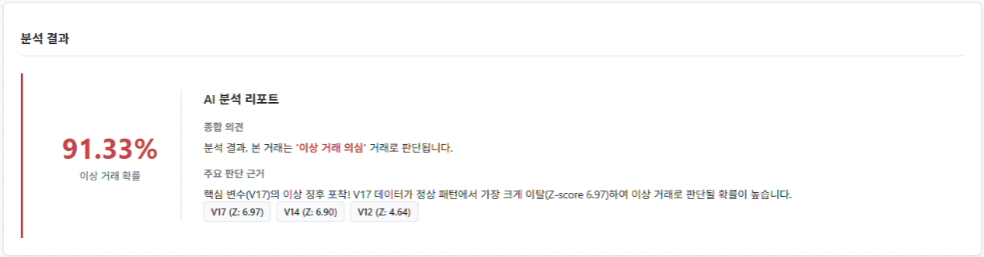
- 단순 예측 결과를 넘어, Z-Score 분석을 통해 **"왜 이 거래가 위험한지"**에 대한 자연어 설명을 자동 생성합니다.
 거래 데이터를 분석하고 그 결과에 대한 내용
거래 데이터를 분석하고 그 결과에 대한 내용
2. 데이터 불균형 해소 (SMOTE)
- 전체 데이터 중 0.17%에 불과한 사기 거래의 학습 효율을 높이기 위해 SMOTE 알고리즘을 적용했습니다.
- Train Set에만 증강을 적용하고 Test Set은 원본을 유지하여 데이터 누수(Data Leakage)를 방지하면서도 높은 재현율을 확보했습니다.
 SMOTE 적용 전후의 데이터 분포 변화 및 성능 향상 지표
SMOTE 적용 전후의 데이터 분포 변화 및 성능 향상 지표
핵심 기술
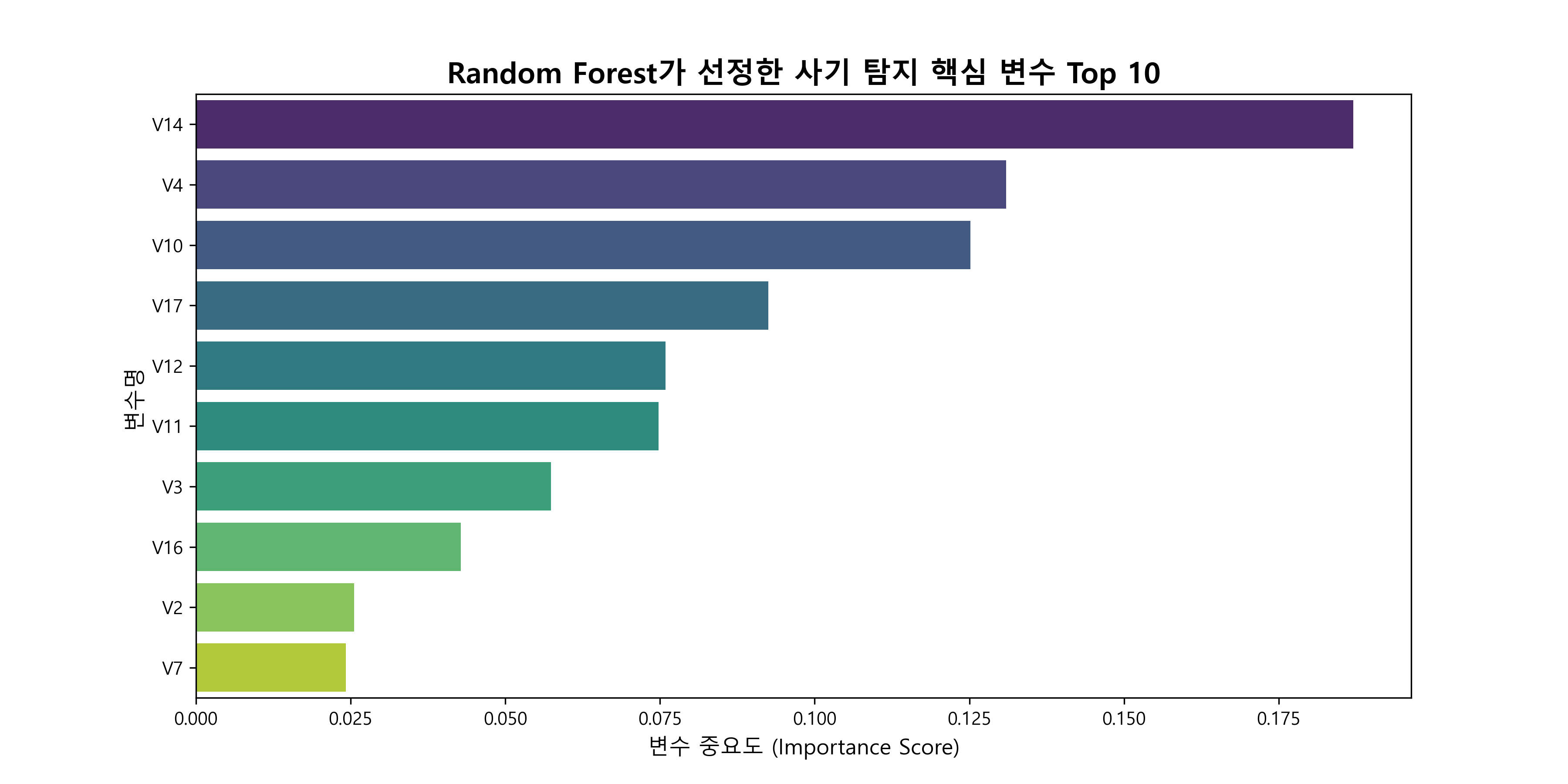
1. 핵심 변수 식별 및 통계적 패턴 분석
PCA로 익명화된 데이터(V1~V28)의 한계를 극복하기 위해 Random Forest의 Feature Importance를 분석했습니다. 그 결과 V14, V4, V10, V17이 사기 탐지의 핵심 지표임을 확인했습니다. 특히 사기 거래 시 V14 값이 급격히 낮아지는(음수 방향) 패턴을 Boxplot으로 검증하여 모델의 신뢰성을 확보했습니다.
2. Z-Score 기반의 이상 징후 설명 로직
블랙박스 모델인 RandomForest의 결과를 해석하기 위해, 통계적 기법인 Z-Score를 활용하여 설명 가능성(Explainability)을 확보했습니다.
# backend/app/api/predict.py
def generate_explanation(input_data: TransactionInput, stats: dict) -> (str, list):
# ... (통계치 로드 및 Z-Score 계산) ...
# Z-score가 높은 순으로 정렬하여 가장 큰 원인 변수 추출
top_feature = z_scores[0]
if top_feature['z_score'] >= 3.0:
# 특정 변수가 극단적으로 튈 때의 동적 메시지 생성
explanation = (
f"핵심 변수({top_feature['feature']})의 이상 징후 포착! "
f"정상 패턴에서 가장 크게 이탈(Z-score {top_feature['z_score']:.2f})하여 "
"이상 거래로 판단될 확률이 높습니다."
)
# ...
return explanation, top_features_list프로젝트 성과
문제 해결 경험: 초기 모델 선정의 실패와 극복
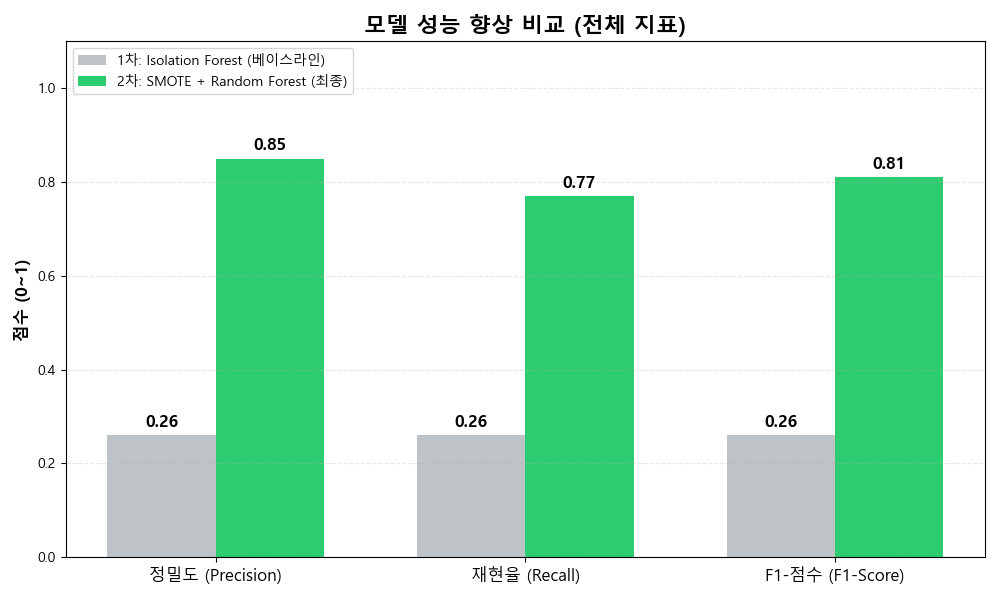
- 도전: 초기에는 라벨이 없는 상황을 가정하여 비지도 학습인 Isolation Forest를 채택했으나, **정밀도와 재현율이 26%**에 그치는 저조한 성능을 보였습니다.
- 원인 분석: 고차원 데이터 공간의 희소성(Sparsity)과 축 평행 분할(Axis-parallel Split)의 한계로 인해, 정상 데이터 분포 내에 교묘하게 위치한 이상치를 격리하지 못함을 발견했습니다.
- 해결: 데이터에 라벨(Class)이 존재한다는 점에 착안하여 지도 학습 모델인 Random Forest로 전환했습니다. 앙상블 기법을 통해 비선형적인 결정 경계를 학습시켰고, SMOTE로 데이터 불균형을 해소한 결과 **재현율(Recall)을 77%**까지 끌어올릴 수 있었습니다.
기술적 성장: 데이터 누수 방지 및 검증
- 데이터 신뢰성 확보: 데이터를 증강하는 과정에서 과적합을 막기 위해 Train/Test 데이터 분리 원칙을 철저히 준수했습니다. 학습 데이터에만 SMOTE를 적용하고, 검증은 원본 비율이 유지된 테스트 셋으로 진행하여 모델의 일반화 성능을 객관적으로 입증했습니다.
- MLOps 파이프라인 경험: Colab에서의 모델 학습부터
.pkl파일 추출, Docker 컨테이너를 통한 3-Tier(React-FastAPI-Postgres) 아키텍처 배포까지 End-to-End ML 서비스 구축 과정을 경험했습니다.
개선할 부분
현재는 정형 데이터(Tabular Data)만을 기반으로 탐지하고 있으나, 추후 사용자의 **접속 위치, 디바이스 정보, 행동 패턴(마우스 움직임 등)**과 같은 비정형 데이터를 결합한다면 더욱 정교한 탐지가 가능할 것입니다. 또한, 탐지된 사기 패턴을 실시간으로 모델에 재학습시키는 Online Learning 파이프라인을 구축하여 신종 사기 수법에 빠르게 대응할 수 있도록 발전시키고 싶습니다.
프로젝트 회고
이 프로젝트는 단순히 머신러닝 모델을 만드는 것을 넘어, **"모델이 실제 비즈니스 환경에서 어떻게 가치를 창출하는가"**에 집중했던 경험이었습니다.
특히 Isolation Forest의 실패를 겪으며 **"무조건 최신 알고리즘이 좋은 것이 아니라 데이터의 특성(분포, 라벨 유무)에 맞는 모델을 선정해야 한다"**는 교훈을 얻었습니다. 또한, 0.17%라는 희박한 사기 데이터를 찾아내기 위해 데이터 증강과 평가 지표(Recall vs Precision)를 고민하며 데이터 사이언티스트로서의 분석 역량을 기를 수 있었습니다.